.NET Compression Libraries Benchmark
I often find myself needing a compression library in a software development project, and after a few tests with disappointing results I usually fall back to spawning 7Zip as an external process. This time however, the application specification prohibits any data written to disk, which 7Zip needs to do in order to work correctly. I needed to do everything in memory, and so I had to test some of the C# libraries available for compression as well as the different compression algorithms.
Here is a full list of the tested libraries:
A compression algorithm can be compared to a small machine that takes in some data, do some math on it and transform it to some new data - just smaller in size. It sounds simple, but it involves a lot of math to do it efficient. The best compression algorithms are the ones which have a high compression ratio while only using small amounts of RAM and CPU. One such algorithm is the very well known DEFLATE which internally uses the famous LZ77 algorithm created by Abraham Lempel and Jacob Ziv. The DEFLATE algorithm has become the de facto standard when it comes to compression, and it is used in nearly all instances when a compression algorithm is needed. There are many compression algorithms out there, some are better than DEFLATE and also very wide spread. Examples include LZW, BWT, LZSS and LZMA.
Each of the compression algorithms only take in a single file, either as a blob of bytes, or a stream of bytes. The question is, how do compression applications such as 7Zip, WinZip and WinRAR compress multiple files?
Enter the world of archive formats. We all know about Zip, BZip2, GZip and RAR. They all simply describe the content of themselves either in terms of files or streams of data, along with some metadata such as original size, file name and path. The archive formats are more complex that you would think, simply because there are a lot of features. Some of them support multiple data streams (for multi-threading), encryption, password protection, file name obfuscation, self-extracting archives and more.
Many of the archiving formats are now synonymous with the compression algorithm they use. We say "Zip the file" or "Make a 7z of the folder". In reality, you can interchange the different archive formats with any of the compression algorithms, and as such you can have combinations such as Zip with LZMA or 7z with DEFLATE. That being said, there are some default compression algorithms in some archive formats. I've listed some examples here in archive/algorithm format:
In the Linux world, the solution to compressing multiple files was solved using an archiving format called Tar. It is a pretty simply format designed for tape archiving, which preserves the filesystem information such as timestamps, owner information and file size on the files held inside the archive. To compress a directory, Tar simply store all the files within the directory inside a single file, then compress it using DEFLATE (gzip) or BWT (bzip2).
The benchmark uses a 128 MB test file that contains images, music, text and some random data. The file represent arbitrary data usually found on a filesystem.
Here is a full list of the tested libraries:
Compression 101
Before I get to the results of the benchmark, I think it is important to understand the different archive formats and compression algorithms in order to compare the results with other benchmarks/and or tests. Lets get to it!A compression algorithm can be compared to a small machine that takes in some data, do some math on it and transform it to some new data - just smaller in size. It sounds simple, but it involves a lot of math to do it efficient. The best compression algorithms are the ones which have a high compression ratio while only using small amounts of RAM and CPU. One such algorithm is the very well known DEFLATE which internally uses the famous LZ77 algorithm created by Abraham Lempel and Jacob Ziv. The DEFLATE algorithm has become the de facto standard when it comes to compression, and it is used in nearly all instances when a compression algorithm is needed. There are many compression algorithms out there, some are better than DEFLATE and also very wide spread. Examples include LZW, BWT, LZSS and LZMA.
Each of the compression algorithms only take in a single file, either as a blob of bytes, or a stream of bytes. The question is, how do compression applications such as 7Zip, WinZip and WinRAR compress multiple files?
Enter the world of archive formats. We all know about Zip, BZip2, GZip and RAR. They all simply describe the content of themselves either in terms of files or streams of data, along with some metadata such as original size, file name and path. The archive formats are more complex that you would think, simply because there are a lot of features. Some of them support multiple data streams (for multi-threading), encryption, password protection, file name obfuscation, self-extracting archives and more.
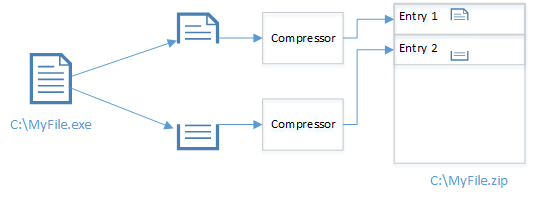 |
| Figure 1: The relationship between files, compression algorithms and archive formats. |
Many of the archiving formats are now synonymous with the compression algorithm they use. We say "Zip the file" or "Make a 7z of the folder". In reality, you can interchange the different archive formats with any of the compression algorithms, and as such you can have combinations such as Zip with LZMA or 7z with DEFLATE. That being said, there are some default compression algorithms in some archive formats. I've listed some examples here in archive/algorithm format:
- Zip / DEFLATE
- 7zip / LZMA
- Bzip2 / BWT
- Gzip / DEFLATE
- GIF / LZW
- PNG / DEFLATE
- Tar / none
- Rar / LZSS
In the Linux world, the solution to compressing multiple files was solved using an archiving format called Tar. It is a pretty simply format designed for tape archiving, which preserves the filesystem information such as timestamps, owner information and file size on the files held inside the archive. To compress a directory, Tar simply store all the files within the directory inside a single file, then compress it using DEFLATE (gzip) or BWT (bzip2).
Benchmark
Now that we know the difference between compression algorithms and archive formats, we can continue to the benchmark. The libraries tested here are overlapping in the sense that they are simply different implementations of different compression algorithms, and even though the name of the library might contain Zip, it has nothing to do with the actual Zip archiving format, but everything to do with the compression algorithm used by default in Zip files.The benchmark uses a 128 MB test file that contains images, music, text and some random data. The file represent arbitrary data usually found on a filesystem.
| Library | Type | Packed (MB) | Pack (ms) | Unpack (ms) | Ratio | Speed (MB/s) |
| .NET 4.5.1 | Zip | 34.10 | 2,921 | 895 | 3.58 | 43.82 |
| ICSharpCode | Zip | 34.07 | 6,373 | 1,524 | 3.58 | 20.08 |
| ICSharpCode | Gzip | 34.07 | 6,347 | 1,511 | 3.58 | 20.17 |
| ICSharpCode | BZip2 | 35.69 | 45,002 | 6,811 | 3.42 | 2.84 |
| 7z SDK | LZMA | 28.51 | 40,235 | 3,254 | 4.28 | 3.18 |
| Zlib.NET | Zlib | 33.97 | 4,837 | 985 | 3.59 | 26.46 |
| DotNETZip | Zip | 33.97 | 5,120 | 1,482 | 3.59 | 25.00 |
| DotNETZip | Gzip | 35.67 | 31,739 | 4,556 | 3.42 | 4.03 |
| DotNETZip | Zlib | 33.97 | 4,509 | 887 | 3.59 | 28.39 |
| LZMA-managed | LZMA | 28.07 | 35,555 | 7,402 | 4.35 | 3.60 |
| QuickLZ | QuickLZ | 42.90 | 1,015 | 1,010 | 2.85 | 126.11 |

Comments
I have a couple of questions.
My main question is about the behavior of compression algorithms in general, so let me preface it with an introduction to my trials to give it context:
I had read from multiple sources that zlib was one of the better compression tools, so I tried using it in my C# application. Surely I found it much better than the inbuilt libraries in VS2008. And yet, for my in-memory message compression (not disk file) requirements, with small byte arrays--around 500 bytes (I tried short messages to begin with)--and using zlib defaults, I did not find much gain, but found the ratios rather inconsistent: 125=>116, 98=>90, 115=>113 (bytes before and after compression).
This brings me to the question: Is this kind of inconsistency in ratio expected of all compression tools; or, does it have anything to do with small byte array inputs, and does it improve with larger inputs? As I see you have also considered a 128MB test file, it further strengthens my doubts that smaller inputs yield inconsistent results.
Would be very glad to learn your thoughts on the above.
Many thanks.
Post a Comment